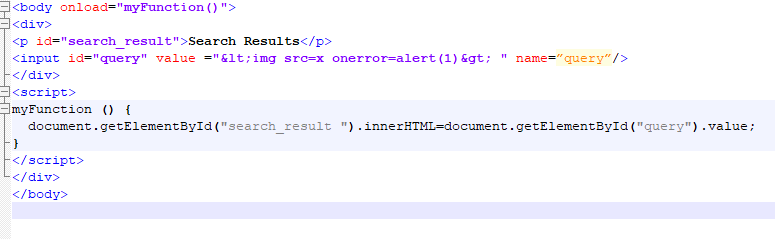
On May 11, 2026, the @tanstack namespace on npm was compromised in a sophisticated supply chain attack. Identified as part of the “Mini Shai-Hulud” campaign, the threat actors did NOT steal maintainer credentials. Instead, they manipulated the project’s legitimate release pipeline to publish 84 malicious versions across 42 packages, including @tanstack/react-router.
This incident demonstrates how minor CI/CD misconfigurations can be chained together using advanced exploitation techniques like Cacheract to compromise highly secure deployment environments.
1. The Root Vulnerability
1.1 The pull_request_target misconfiguration
The entry point for this attack was a severe misconfiguration within TanStack’s benchmarking workflow, bundle-size.yml.
To manage community contributions, GitHub Actions offers two distinct triggers for handling Pull Requests: pull_request and pull_request_target.
| Security feature | pull_request (secure default) | pull_request_target (vulnerable if misconfigured) |
|---|---|---|
| Execution context | Runs in the context of the untrusted fork. | Runs in the context of the trusted base repo (main). |
| Secret access | Completely blocked from repository secrets. | Has full access to repository secrets. |
| Cache write scope | Isolated strictly to the fork branch. | Mapped directly to the default (main) branch. |
1.2 The “Pwn Request” Configuration
The workflow authors used pull_request_target because they wanted the pipeline to automatically write benchmark comparisons as a comment back onto incoming PRs.
The catastrophic flaw lay in how the workflow handled the code checkout and execution:
on:
pull_request_target: # Runs with elevated base repository privileges
jobs:
benchmark:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
# MISCONFIGURATION 1: Checking out untrusted code from the attacker's fork
ref: ${{ github.event.pull_request.head.sha }}
- name: Run Build Benchmarks
# MISCONFIGURATION 2: Executing untrusted scripts in a privileged context
run: pnpm nx run @benchmarks/bundle-size:buildBy explicitly checking out the untrusted pull request SHA (github.event.pull_request.head.sha) and running its build scripts, the workflow executed attacker-controlled code inside a pipeline running under the context of the main branch scope.
1.3 Breaking the Boundary: Package Manager Cache Isolation
To understand how the attacker capitalized on this access, we must look at how modern continuous integration pipelines optimize build times.
Instead of downloading thousands of Node modules from the public registry on every single run, repositories use dependency caching. TanStack utilized a standard, deterministic cache key format mapped to a hash of the project’s lockfile:
- uses: actions/cache@v5
with:
path: ~/.local/share/pnpm/store
key: Linux-pnpm-store-${{ hashFiles('**/pnpm-lock.yaml') }}1.4 The Isolation Bypass
GitHub enforces cache security boundaries by Git branch scopes. Under normal circumstances, a workflow running on a pull request fork cannot overwrite or corrupt the cache assets belonging to the main branch.
However, because the pull_request_target misconfiguration forced the entire runner container to evaluate under refs/heads/main, the attacker’s fork inherited direct write permissions to the base repository’s central cache storage.
2. Deep Dive: The Mechanics of a Cacheract Attack
The threat group executed this cache hijacking using Cacheract, an attack methodology originally detailed by security researcher Adnan Khan. This technique allows a threat actor to leverage the internal architecture of a GitHub runner to bypass standard step-level token restrictions. To follow this concept, you need one concept that isn’t obvious unless you’ve written GitHub Actions before.
Every GitHub Action can register a cleanup script. When you write uses: actions/checkout@v4, you’re not just running one block of code — you’re registering an action that has both a “main” step and a separate “post” step that runs automatically after all your workflow’s main steps finish. It’s how actions/checkout removes SSH keys it added, how cache actions save state on the way out, and so on. You don’t write these cleanup scripts. You don’t see them in your workflow YAML — they just run when you configure a GitHub action.
Here’s the catch: the cleanup phase runs in a slightly more privileged context than your regular steps. GitHub’s runner needs to be able to clean up its own internal state — saving caches, removing tokens — so during cleanup it makes available an internal credential called ACTIONS_RUNTIME_TOKEN. This token authorizes direct reads and writes to GitHub’s cache backend. The permissions: contents: read setting in your workflow does nothing to restrict it, because it’s the runner orchestrator’s token, not the workflow’s GITHUB_TOKEN. (This is exactly why the permissions: contents restriction added by the author of the GitHub workflow is not effective.)
An analogy: think of a workflow like a building that has business hours and after-hours cleaning. During business hours (your main steps), everything is locked down — your GITHUB_TOKEN only has the permissions you explicitly granted, doors require badges, security cameras are on. After business hours (the cleanup phase), the cleaning crew comes through with master keys. They’re trusted, they have access to backend systems, and nobody watches what they do because it’s all routine. If an attacker can leave instructions for the cleaning crew, they don’t need to break into the building during the day — they get all of the cleaning crew’s after-hours access.
2.1 Bypassing Step-Level Restraints
That’s exactly the attack. While the attacker’s build script was running as a normal workflow step, it navigated to the runner’s local on-disk storage for installed actions, found the JavaScript file that actions/checkout had registered as its post-step cleanup, and overwrote that file with the attacker’s own code. From the runner’s point of view, nothing suspicious happened — a build step modified some files in the runner’s working directory, which is allowed.
The author of the workflow had attempted to restrict the job by adding permissions: contents: read. They assumed this would prevent the script from modifying the repository or altering state.
However, GitHub’s caching infrastructure completely bypasses the standard GITHUB_TOKEN. When a runner manages caches, GitHub’s orchestrator automatically injects two hidden backend environment variables into the runner context:
ACTIONS_CACHE_URL: a dedicated cloud storage API endpoint.ACTIONS_RUNTIME_TOKEN: a temporary bearer token authorizing network read/write operations directly to the repository’s cache server.
2.2 Clobbering the Post-Checkout Lifecycle Hook
To evade detection and avoid logging suspicious network traffic during the explicit workflow steps, the attacker’s setup script (vite_setup.mjs) used a post-checkout “clobbering” technique. It involves three steps.
2.2.1 Navigated to the runner’s hidden execution directories
A GitHub Actions runner (the VM your workflow runs on) has a specific filesystem layout that workflow authors almost never think about. The directories aren’t “hidden” in the dotfile sense — they’re plain visible directories that just happen to live outside your repo checkout, so nobody looks at them. The relevant ones:
/home/runner/work/<org>/<repo>/— where your code is checked out. This is where you spend your time when debugging a workflow./home/runner/_work/_actions/— where the runner downloads the source code of every action youuses:before running it. This is the directory the attacker was after.
When your workflow says uses: actions/checkout@v4, the runner does roughly the equivalent of git clone --depth=1 https://github.com/actions/checkout && git checkout v4, but it puts the result inside /home/runner/_work/_actions/actions/checkout/v4/. So on the runner’s disk you end up with a real, modifiable copy of actions/checkout‘s entire source code, including its compiled JavaScript bundle. The path looks like:
/home/runner/_work/_actions/actions/checkout/v4/ ├── action.yml ├── dist/ │ └── index.js ← the code the runner actually executes ├── package.json └── ...
There’s no special permission gate around it. The workflow’s process — including any run: step you have — runs as the user runner, and the runner owns these files. Your build script can cd there and cat or rm or > overwrite whatever it wants. The runner doesn’t check.
2.2.2 Overwrote the post-script files belonging to actions/checkout
Every GitHub Action has a manifest file (action.yml) at its root that tells the runner how to run it. For actions/checkout, that manifest declares both a main JavaScript entry point and a post JavaScript entry point:
# actions/checkout/v4/action.yml (simplified)
runs:
using: 'node22'
main: 'dist/index.js' # runs during your workflow's main steps
post: 'dist/index.js' # runs during cleanup
post-if: 'success()'In practice, actions/checkout uses the same compiled bundle for both phases and switches behavior internally based on an env var the runner sets, but the relevant fact for the attack is that the runner re-reads that JavaScript file from disk when it’s time to run cleanup.
The attacker’s malicious build step did the equivalent of:
cd /home/runner/_work/_actions/actions/checkout/v4
echo '<attacker JS payload>' > dist/index.jsIt didn’t touch action.yml. It didn’t rename anything. It just replaced the contents of the file that the runner was going to load again, soon, automatically, with elevated privileges.
The runner has no integrity check on this. There’s no signature verification, no “did the SHA-256 of this file change since download” check, no read-only filesystem protection on the actions directory. Once actions/checkout was downloaded by the runner at the start of the workflow, the bytes in dist/index.js were just bytes on a writable disk.
2.2.3 The runner entered its Post-Action Lifecycle Phase
When a workflow runs, the runner follows a strict lifecycle that the workflow author neither defines nor controls. It looks roughly like this:
Phase 1 — Setup
└─ Download every uses: action into /home/runner/_work/_actions/
Phase 2 — Main steps
└─ For each step in your workflow, run it in order
(this is where your build script lives)
Phase 3 — Post steps (mandatory, automatic)
└─ For every action that declared a "post:" entry in its manifest,
run that entry point now, in reverse order of the main steps
You don’t write it into your workflow. You can’t disable it. The runner walks its internal list of “actions that registered a post step” and executes each one. For each, it loads the JS file from disk and runs it as a Node.js script.
Two things make this phase special from an attacker’s perspective. First, the runner injects ACTIONS_RUNTIME_TOKEN and ACTIONS_CACHE_URL into the environment so cleanup code can talk to GitHub’s cache and artifact backends — this is exactly the credential the attacker wanted. Second, the runner trusts the on-disk JS files implicitly; it has no concept of “verify this is the same file we downloaded in Phase 1.”
So when the runner reached Phase 3 and tried to run actions/checkout‘s post step, it loaded dist/index.js (which now contained attacker code), executed it as Node, and made the runtime token available in process.env. The attacker code read the token, opened an HTTPS connection to GitHub’s cache backend, and uploaded the 1.1 GB poisoned pnpm store.
From the runner’s logs, this looked like actions/checkout performing its normal cleanup. There was no run: step in the YAML that did the upload. The workflow definition was, by that point, irrelevant — the malicious code was running inside the trusted post-step machinery.
2.3 Cache Stuffing and Replacement
After uploading the poisoned cache, the attacker force-pushed a blank commit to their PR branch and closed the PR. No code remained anywhere in any visible branch. No audit trail except a cache write that no maintainer was watching.
Eight hours later, a TanStack maintainer pushed a routine documentation update to main. That commit was clean. The maintainer wasn’t compromised. But the commit triggered the official release.yml workflow, which executed the standard cache-restore step:
The release pipeline was using OIDC (permissions: id-token: write) — passwordless, short-lived, generally considered the correct way to authenticate to npm. The malware didn’t need a stolen long-lived secret. It just needed to be running inside the same process when OIDC handed the build a fresh token, and it scraped that token from process memory before it could be used.
From npm’s perspective, the publish came from the real release runner, signed by the real OIDC chain, with a real SLSA provenance attestation. Everything verified. Only the payload was poisoned.
3. The Delayed Execution: How the Trap Was Sprung
Once the cache was successfully poisoned, the attacker force-pushed a completely blank commit to the pull request branch to erase visible change logs and closed the PR. No malicious code remained in any open branch or code review window.
The compromised payload sat quietly on GitHub’s backend for nearly eight hours until an entirely unrelated event took place: a core maintainer pushed a safe documentation update straight to the main branch.
This pushed commit triggered the official production release.yml workflow.
- The Retrieval: the release runner executed its cache retrieval step, generated the deterministic key string, matched it to the poisoned archive, and extracted the malicious 1.1 GB dependency store onto the machine.
- The Execution: when the pipeline issued its standard
pnpm buildcommand, pnpm read directly from the local store rather than downloading clean modules from the internet. - The Compromise: the malicious binaries executed on the highly secure release runner. Because the release pipeline required permissions to publish to npm via passwordless OpenID Connect (
permissions: id-token: write), the malware used a memory dumper to scrape/proc/<pid>/mem, lift the active OIDC token from the worker process, and publish compromised packages to the npm ecosystem with a valid SLSA provenance attestation.
Key Takeaways for Securing CI/CD Pipelines
The TanStack breach underscores that security boundaries in CI/CD are absolute; once a privilege boundary is crossed, standard permission gates fail. To defend against cache poisoning and Cacheract-style attacks, implement the following guardrails:
- Never check out untrusted PRs in
pull_request_target: if you must usepull_request_targetto interact with PR data (such as posting comments), do not check out code or run scripts originating from the fork. Keep code execution strictly confined to thepull_requesttrigger. - Isolate cache keys by scope: prevent cross-boundary poisoning by adding the runner’s execution context or branch reference directly into your cache keys (e.g.,
key: ${{ github.ref_name }}-pnpm-store-${{ hashFiles('**/pnpm-lock.yaml') }}). This ensures a PR can never generate a key that matches a production release key. - Pin actions to immutable commit SHAs: avoid using mutable version tags (like
@v4) for actions in highly privileged workflows. Pin actions to a specific, auditable Git commit SHA to prevent runtime environment tampering.