I’ve been doing application security for over a decade. I’ve reviewed thousands of pull requests, written threat models for systems serving millions of users, and built static analysis rules that catch exactly this class of bug.
And I still shipped a stored XSS in a side project. Here’s what happened, and why it’s a bug that catches even people who should know better.
The takeaway, up front
If you’re skimming, here’s the one thing to remember:
Your templating engine’s auto-escape protects HTML contexts, not JavaScript contexts. When user data is rendered inside a <script> block or an inline event handler like onclick, EJS’s <%= %> (or any equivalent in Pug, Handlebars, etc.) is not enough. You need JSON.stringify.
Everything below is evidence and explanation for why this trips people up — including people whose job is to catch this.
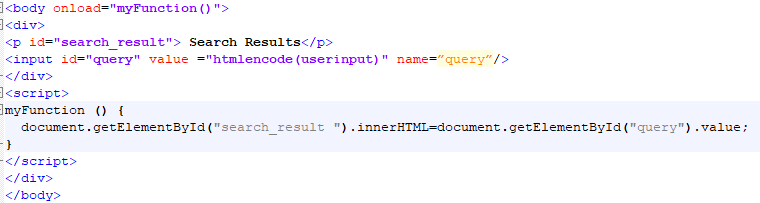
The vulnerable code
This is the line that bit me. It’s the delete button on an admin user-management page:
<button onclick="confirmDelete(<%= user.id %>,
'<%= (user.name || user.email).replace(/'/g, "\\'") %>')">
If you spotted the bug, you don’t need this post. If it looks fine to you — keep reading. That’s exactly the point.
The developer (me) did two things that feel defensive:
- Used EJS
<%= %>, which HTML-encodes its output automatically - Added
.replace(/'/g, "\\'")to escape single quotes with a backslash
Two layers of escaping. Should be safe. It isn’t.
The exploit
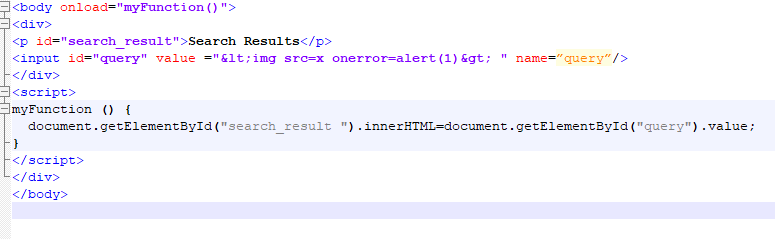
An attacker registers with this name:
test\');alert(document.cookie);//
EJS renders the button as:
onclick="confirmDelete(28, 'test\\');alert(document.cookie);//')"
The ' became '. The \ doubled to \\. Looks encoded. Looks safe.
It isn’t.
The decode chain — where the bug actually lives
Here’s what the browser does before that JavaScript executes. This is the part most developers (and most XSS writeups) don’t walk through carefully.
Step 1 — HTML attribute parsing
The browser decodes HTML entities in attribute values before passing the content to the JavaScript engine:
\\ → \ (two characters become one literal backslash)
' → ' (HTML entity becomes a literal quote)
Step 2 — what the JavaScript engine actually sees
confirmDelete(28, 'test\');alert(document.cookie);//')
Step 3 — JavaScript string parsing
'test— string starts\\→\— JS interprets the double-backslash as one literal backslash'— the string closes here — the backslash escape was already consumed);— closesconfirmDelete(alert(document.cookie);— executes//— comments out the trailing junk
The modal never opens. The alert fires. Stored XSS confirmed.
Why my “escaping” failed
The intuition behind .replace(/'/g, "\\'") is reasonable: put a backslash before a quote so JavaScript treats it as a literal.
It’s true that \' escapes a quote in a JS string literal. But the backslash itself needs to survive HTML decoding first. When \\ appears in the HTML source, the browser decodes it to a single \ before JavaScript ever sees it. So the JS engine sees \' — and yes, that does correctly escape the quote.
So shouldn’t that protect against the attack?
Here’s the twist that closes the loop. The attacker put two backslashes in their name (test\\'...). EJS doubles each one (HTML-encodes them) to produce \\\\ in the page source. After HTML attribute parsing: \\. After JavaScript string parsing: a single literal backslash — and the next ' closes the string after all.
The escaping and the encoding interfered with each other in exactly the wrong way. Each layer was trying to be defensive, but together they created a hole neither would have created alone.
This is the part that’s hard to spot in code review. The line looks defensive. You see the .replace() and your brain goes “okay, quotes are handled.” It’s only when you trace what each layer actually does to the bytes that the bug becomes visible — and that’s not a thing most reviewers do for a single line of template code.
Why this still happens to people who should know better
I want to be honest about why I shipped this, because I think the reasons generalize.
1. EJS’s <%= %> feels universally protective. The whole point of auto-escape is “you don’t have to think about XSS.” That mental shortcut works in HTML contexts and silently fails in JavaScript contexts. The engine is doing what it was designed to do — HTML-encoding. The developer mistake is assuming HTML encoding protects everywhere.
2. The line looks like the developer thought about it. The .replace(/'/g, "\\'") is more defensive than no escaping at all. In code review, “they handled the quotes” is a thought that ends review of that line. The reviewer doesn’t usually trace the decode chain.
3. Stored XSS in admin contexts is invisible during normal development. The exploit only fires when an admin views the page. As a developer testing your own UI, you never see it. You’d need a separate attacker account registering malicious names to notice. Most side-project authors don’t have that kind of test setup.
4. JavaScript string contexts are easy to miss. When you’re writing onclick="...", you’re thinking about the inline handler as just an attribute. You don’t always pause to think “this attribute value is JavaScript that gets parsed twice — once by the HTML parser, once by the JS engine.”
I knew all four of these things in theory. I shipped it anyway. That’s why I think this post is worth writing — knowing the rule isn’t enough. The pattern that surfaces the bug has to be automatic, and for me it apparently wasn’t, even after a decade.
The fix
One line:
<!-- Before -->
onclick="confirmDelete(<%= user.id %>, '<%= (user.name || user.email).replace(/'/g, "\\'") %>')"
<!-- After -->
onclick="confirmDelete(<%= user.id %>, <%= JSON.stringify(user.name || user.email) %>)"
JSON.stringify produces a properly quoted, properly escaped JavaScript string literal. It handles single quotes, double quotes, backslashes, newlines, Unicode escapes, line separators — every character that could break out of a JS string context. It’s the right tool for injecting data into JavaScript, because it was designed for serializing data into JavaScript-parseable form.
HTML entity encoding wasn’t.
The rule worth remembering
HTML encoding protects HTML contexts. JSON encoding protects JavaScript contexts. Using the wrong one gives you false confidence while leaving the door open.
Whenever user input lands inside a <script> block or an inline event handler like onclick, onmouseover, onload — that is a JavaScript context, not an HTML context. JSON.stringify is the tool. The templating engine’s auto-escape is not.
Auto-escape is not a universal XSS shield. It is context-specific, and JavaScript is a different context.
What I changed beyond the fix
A one-line patch fixes the immediate bug, but it doesn’t fix the conditions that let me ship it. A few things I’m doing in the project going forward:
- Lint rule for inline event handlers with EJS interpolation. Any
<%= %>or<%- %>inside anonclick/onload/onsubmitetc. attribute is now a CI failure unless the value is wrapped inJSON.stringify. data-*attributes + addEventListener instead of inline handlers, where practical. Pulling JS out of HTML attributes removes the dual-parsing surface entirely.- Adversarial test data in the registration flow. A small set of payloads (including
\\'patterns) gets seeded into the user list during integration tests, and any admin page that renders user data has to render those entries safely. Catches this whole class of bug, not just this instance.
The lint rule is the highest-leverage of the three. It’s a 30-line ESLint plugin and it would have caught this exact bug.
Closing thought
A decade of doing AppSec doesn’t make you immune to AppSec bugs. It makes you better at finding other people’s. Your own code is harder, because the same intuitions that helped you ship fast also helped you skip the careful review.
That’s not a reason to be embarrassed. It’s a reason to build the catch into tooling, not into willpower.