Input validation is a widely adopted technique in software development to ensure proper user input data to be processed by the system and prevent malformed data from compromising your system. If a robust input validation method is adopted, input validation can significantly reduce the common web attacks, such as injections and XSS, though it should not be used as the primary method to combat these vulnerabilities.
However, to implement a robust validation method is a very challenging task, you may have to consider many aspects, for example, 1) which input validation method should be used, blacklist, whitelist or regex based 2)when input validation should be performed 3)is the input validation efficient. 4) how to ensure input validation is executed in multiple components in a complicated architecture.
Without a careful consideration of all these areas, your input validation might be flawed and turns out useless to combat malicious user input.
Common mistakes when implementing input validation
Here are some common mistakes observed when performing penetration tests and code reviewing.
- Confuse Server Side validation with Client Side Validation
- Perform Input Validation before proper decoding
- Poor validation Regex leads to ReDOS
- Input validation implemented without the context of the entire system
- Reinvent the wheel by creating your own input validation method
- Blacklist input validation is not comprehensive
Confuse Server Side Validation with Client Side validation
Client Side validation is for user experience/usability, which is more likely to be performed by your browsers during executing some JavaScript code; whereas, server side validation is employed for security control, which is used to ensure proper data is supplied to the server or service. In another word, client side validation does not add any security enhancements to your application.
Nowadays, many web frameworks, for example, Angularjs and react, offer client side input validation to improve user experience and make developers life easier. For example, the following input field will validate whether the user input is a valid email address.
| <html><script src=”https://ajax.googleapis.com/ajax/libs/angularjs/1.6.9/angular.min.js”></script> <body ng-app=””> <p>Try writing an E-mail address in the input field:</p> <form name=”myForm”><input type=”email” name=”myInput” ng-model=”myInput”></form> |
This build-in client side validation gives a wrong feeling to the developers that input validation has been done by the framework already. As a consequence, Server side validation is not implemented and any attacker could bypass the client input validation and launch a potential attack.
Solutions
Educate your developers and test engineers to understand the difference between client side validation and server side validation so that the correct validation method is implemented.
Perform validation before decoding the input data
As you might be advised when implementing input validation, it should happen as soon as the data is received by the server in order to minimize the risk. That is a true statement and input validation should be executed before the user supplied data is consumed by the server.
When running some bug bounties programs. I found it is very common that the input validation is executed at the wrong time. Sometimes, the input validation is performed before it is converted to the correct format in which the system would consume.
For example, in one test case, an application is vulnerable to XSS vulnerability through a parameter https://evils.com/login?para=vuln_code. An input validation is performed to check whether it contains malicious code, input like javascript:alert(1) or java%09script:alert(1) will be blocked. However, if an attacker changes the payload into Hex format, the input validation method is not able to detect the malicious code.
| \x6A\x61\x76\x61\x73\x63\x72\x69\x70\x74:\x64\x6F\x63\x75\x6D\x65\x6E\x74\x2E\x74\x69\x74\x6C\x65\x3D\x61\x6C\x65\x72\x74\x28\x31\x29 |
Solutions
When input validation is executed, you need to ensure you are validating the user input in the same format in which the System or service would consume. Sometimes, it is necessary to convert and decode the user input before applying input validation functions.
Improper Regex Pattern for validation leads to ReDOS
Many input validations are leveraging regular expressions to define an allowlist for input validations. This is a great way to create allowlist without adding too much restriction on the user input data. However, developing a robust and functional regex is complicated. If not handled properly, it could do more harm than good to your application.
Take the following regex for example, the regex is used to check whether a HTML page is using application/json format JavaScript code for JSON before scraping it by the server.
| var regex = /<script type=”application\/json”>((.|\s)*?)<\/script>/; |
This regex will lead to ReDOS attack because it contains a so-called “evil regex” pattern ((.|\s)*?) which could introduce backtracking problems.
Here is a POC to demonstrate how long it will take to evaluate the regex when increasing the test string.
| var regex = /<script type=”application\/json”>((.|\s)*?)<\/script>/; for(var i = 1; i <= 500; i++) { var time = Date.now(); var payload = “<script type=\”application/json\”>”+” “.repeat(i)+”test”; payload.match(regex) var time_cost = Date.now() – time; console.log(payload); console.log(“Trim time : ” + payload.length + “: ” + time_cost+” ms”); } |
A detailed example could be found in another blog post, ReDOS, it could be the cause of your next security incident, that will give you a better explanation about how ReDOS occurs and how it could damage your applications.
Solutions
To create a very robust regex is hard, but here are some common method you might follow
- Set the length limitation if possible
- Set a time t limitation for the regex matching. If the regex matching is taking too long than expect, just kill the process
- Optimize your regex with Atomic grouping to prevent endless backtracking.
Input validation without clear context of the entire system
With more and more businesses adopting microservices, the micro-services architecture sometimes could bring challenges for input validation functions. When data flows between multiple microservice, the input validation implemented for microservice A might not be sufficient for microservice B; or input validation is not implemented for all the microservices due to lack of centralized input validation functions.
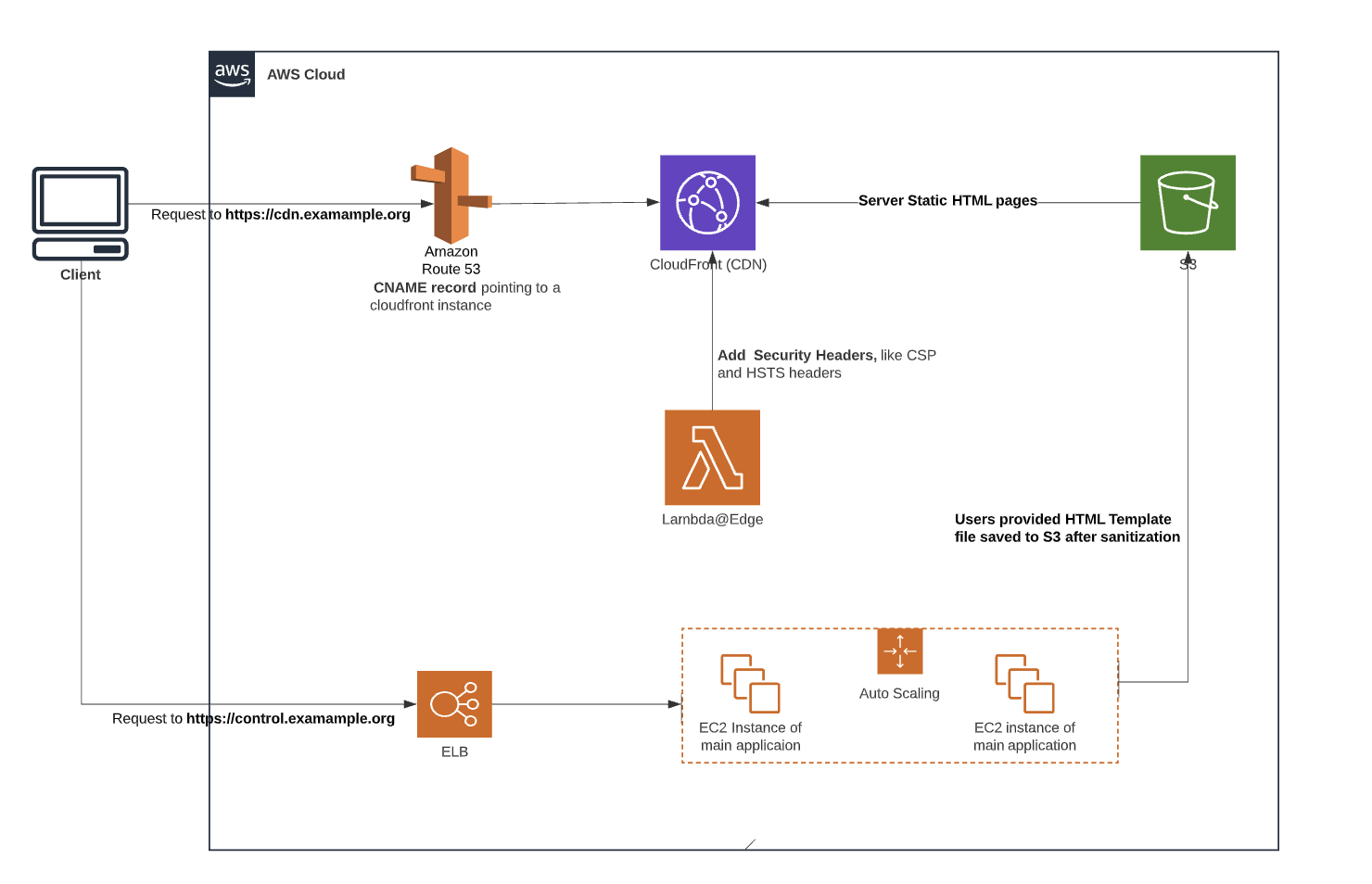
In order to illustrate this common mistake better, I would like to use the following typical AWS microservice diagram as an example.

Here are two scenarios where input validations could go wrong
Scenario 1 Input validations not implemented for all microservice
In some scenarios, there might be multiple services behind the API Gateway to consume the user input data. Some services might have to give response to the user input directly, for example, Service B in the above diagram; whereas, some microservice are designed to handle some background jobs, for example, Service A and Service C.
Since service A and service C are implemented for some background jobs and they do not respond to the user input directly, the developers might ignore implementing input validation for these two services if a centralized input validation is not enforced for this microservice architecture. As a consequence, lack of input validation in service A and Service C could lead to exploitation.
Scenario 2 Input validation for one service is insufficient for its downstream services.
In this scenario, input validation is implemented for microservice B and it is sufficient for microservice B to block malicious user input. However, the input validation might not be sufficient for its downstream Service D.
A good example could be found under my previous blog post Steal restricted sensitive data with template language The microservice B is validating whether user input is a valid template. The input validation implemented in microservice B is robust for this service. However, when service D is compiling the user input template validated by microservice B with some data to get the final output, the process could lead to data leakage because microservice D is not validating the compiled template.
Solutions
Before implementing the user input validations, the developers and security engineers should obtain a comprehensive understanding of the entire system and ensure input validation should be applied in all the components/microservices.
“Reinvent the wheel” by creating your own input validation methods
Another common mistake that I observed when performing code reviewing, is that many engineers are creating their own input validation methods though there are very matured input validation libraries used by other organizations.
For example, if you need to validate whether the input is an email address or the input is a valid credit card number, you have many options to choose from matured input validation libraries. Creating your own validation method is time consuming and it could be defective without robust tests.
Solution
To avoid “Reinvent the wheel”, you need to figure out the purpose of your input validation and try to search whether there are existing validations already implemented. If there are some popular libraries you could use, try to use the existing libraries instead of creating new ones.
Blacklist is not comprehensive
One of the most popular quotes you are seeing frequently is “You could not control things that you could not measure”. This quote could explain the pain of using the blacklist method for user input validation.
Blacklist approach in Input validation is to define which kind of user inputs should be blocked. With that said, developers and security engineers need to understand what inputs are considered “bad” and should be blocked by the blacklist. The efficiency of the blacklist method is largely dependent on the knowledge of the developers and their expectation of bad user inputs.
However, security incidents or breaches are most likely to occur when malicious users are injecting something unexpected.
Solution
In many cases, blacklisting and whitelisting are implemented together to meet the requirement. If possible, try to employ both methods to combat malicious user inputs.
Conclusion
It could not be overemphasized how import input validation could be used to help your organization to combat malicious attacks. Without a robust input validation method in your service or system, you are likely to open the door for potential security incidents.
It could be super easy to start implementing input validations in your service, but you really need to pay attention to these common mistakes found in many validation methods. Try to understand your system or service, choose the right validation methods suitable for your organization, once decided try to perform a thorough testing against your method.